I metodi di Machine Learning sono dei metodi che si sono sviluppati negli ultimi anni nella statistica e hanno come obiettivo quello di creare dei modelli previsivi automatici dove il ruolo cruciale viene intrapreso dalla macchina.
La macchina infatti apprende man man che si inseriscono data-set il comportamento di un certo tipo di popolazione e si allena su questo (training set).
Dopodiché apprese le caratteristiche fondamentali vengono effettuate delle previsioni sul test-set mettendo in primo piano una determinata variabile obiettivo (target).
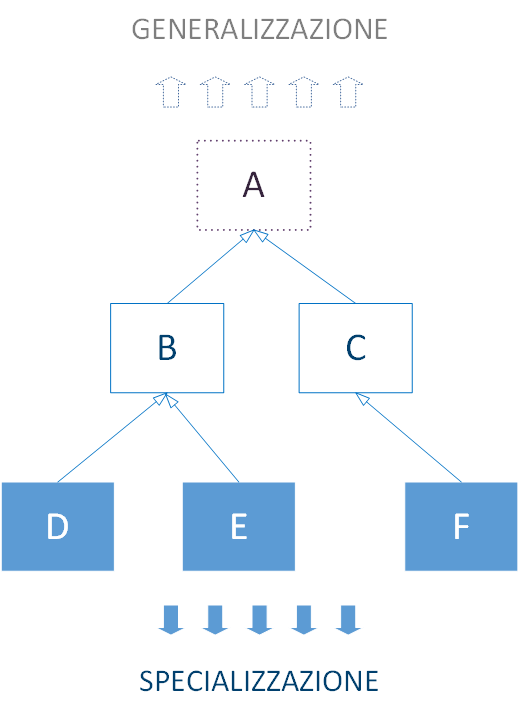
I metodi più diffusi sono quelli basati sugli alberi decisionali che si pongono come obiettivo quello di effettuare una classificazione (variabile target qualitativa) o regressione (variabile target quantitativa) dei dati.
I più conosciuti sono i metodi Bagging, Random Forest e Gradient Boosting. Non basati sugli alberi decisionali ci sono invece le reti neurali e le support Vector machine (SVM).
Le Random Forest appartengono, così come il Bagging, alla classe di metodi Ensamble di tipo Average: l’idea base è di costruire diversi stimatori in modo indipendente e di fare una media delle previsioni sapendo che lo stimatore combinato è spesso migliori di qualsiasi singolo stimatore poiché avrà una varianza ridotta.

Con l’uso del Random Forest il risultato che si ottiene non è un singolo albero ma una foresta di alberi; in una seconda fase gli alberi vengono aggregati così da ottenere un unico classificatore.
La differenza cruciale tra Bagging e Random Forest è che in queste, nella costruzione di un singolo albero, non si usa tutto l’insieme delle variabili, ma un suo sottoinsieme.
Se infatti considerassimo tutte le variabili, i primi “split” nei vari alberi sarebbero fatti sempre nel medesimo modo e otterremmo dei risultati molto simili.
Scegliendo casualmente un sottoinsieme delle variabili per ogni (albero) campione Bootstrap si possono fare diverse prove per vedere di volta in volta quale variabile in quel nodo porta allo “split ottimo”.
Il Random Forest considera all’interno del singolo albero solo un sottoinsieme delle variabili su campioni bootstrap di n unità, e la selezione delle variabili è casuale ad ogni split. Ovviamente si devono determinare a priori alcuni parametri come numero di variabili da scegliere casualmente ad ogni split, numero di alberi da creare, numerosità massima all’interno di una foglia e così via.










![\sigma^2_X=\mathbb{E}[X^2]-\mathbb{E}[X]^2\](https://i1.wp.com/upload.wikimedia.org/math/1/6/b/16b6a27dc0f312e09eea7390ba9951f6.png)